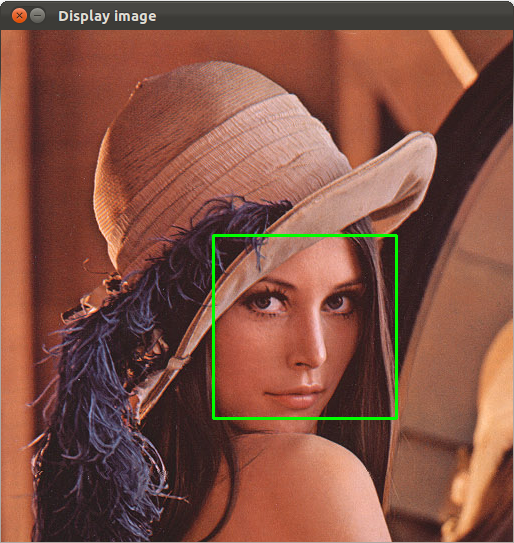
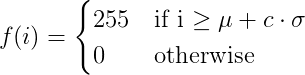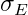Face Miner is based on the paper of Wen-Kwang Tsao at al.: "A Data Mining approach to Face
Detection".
In Face Miner, a critical discussion of the paper has been done. Therefore Face Miner
is not a
reproduction of the work described in the paper, but a different implementation resulting
from this critical discussion.
The
original paper was not reproducible due to the usage of private datasets and, as a conseguence,
the resulting work was publicly available.
Face Miner is FOSS, completely reproducible and the available on
GitHub:
https://github.com/galeone/face-minerThe datasets used are:
Yale Face Database B: http://vision.ucsd.edu/~leekc/ExtYaleDatabase/ExtYaleB.htmlMIT CBCL Face Database: http://cbcl.mit.edu/software-datasets/FaceData2.html